{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
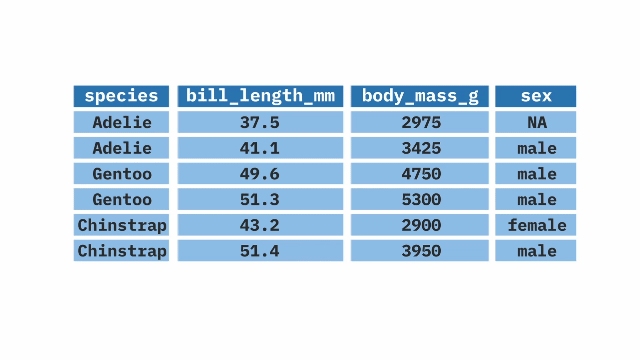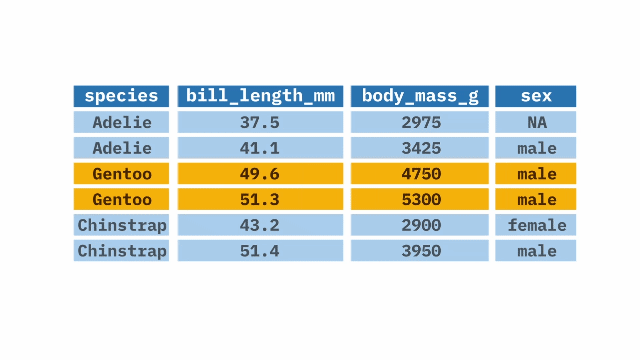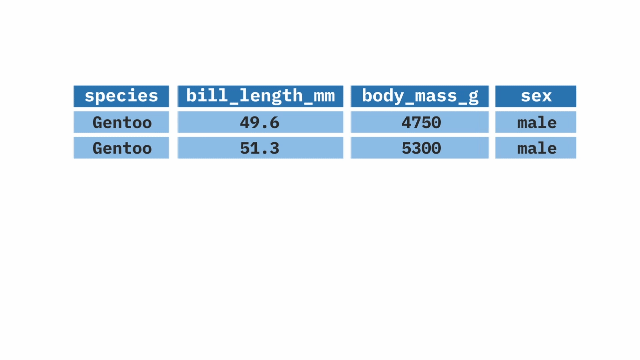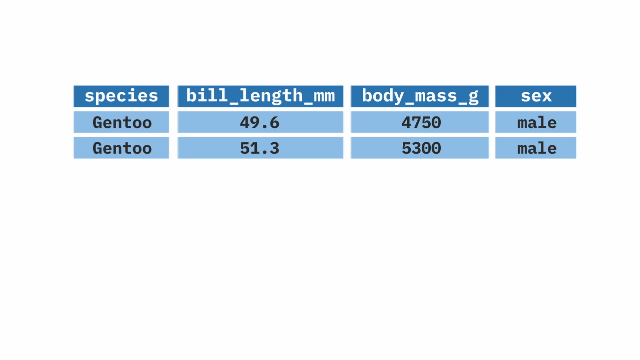
- 1
- Take the ethiopia_small dataset, and then
- 2
- filter it so that we only keep responses to question Q254 where the respondent says “Very Proud.”
6 Managing Data
The Passion Driven Statistics video calls this section of the course data management. I prefer data wrangling. You are trying to get control of your data so that you and your data can get work done.

Much of the work of anyone who works with quantitative data is data wrangling: creating a dataset for the particular task you have in mind. Work might include subsetting data, filtering data, creating new variables, or making the data easier to understand.
Much of the essential work has been done for you. The datasets you will start with are in R format, but you will need to do some data wrangling.
To do most of this work, you will use an R package, {dplyr}, part of the {tidyverse}, a group of packages created to make working with data more manageable. Specifically, the functions you will be using are:
- select — choose variables from a dataset to include or exclude animation example
- filter — pick observations, rows, in a dataset by their values animation
- mutate — create new variables animation
The animations are from Rfortherestofus.
Other major functions are:
- summarize — collapse many values into a single summary. Summarize can also be combined with group_by to create summaries for groups such as by political party or an area where people live. animation
- arrange — rearrange the rows in a dataset animation
These functions can be combined with other packages to wrangle data in impressive ways. This chapter will give examples of using these verbs for everyday data management tasks.
6.1 A Detour: 3 Operators
Before we look at these functions we first need to look at three operators that will help us do our work. You may have seen them already in templates. Here we will formally introduce them.
6.1.1 Pipes
First, let’s formally introduce the pipe, that weird |> (or %>%) symbol we’ve used occasionally. It can be useful to translate the pipe as “and then”: do this, “and then” do the next thing. Pipes allow you to send the output from one function straight into another function. Specifically, they send the result of the function before |> or (%>%) to be the first argument of the function after |> (or %>%). It’s easier to show than tell, so let’s look at an example.
6.1.2 The <- Operator
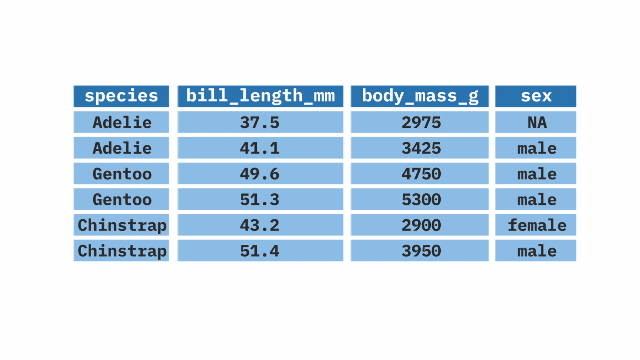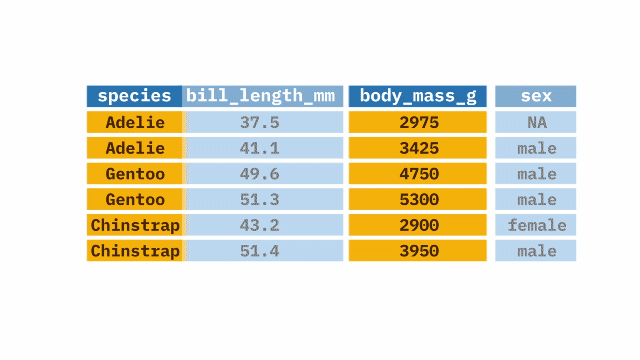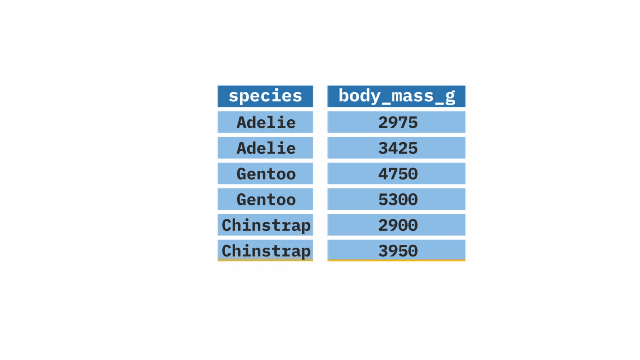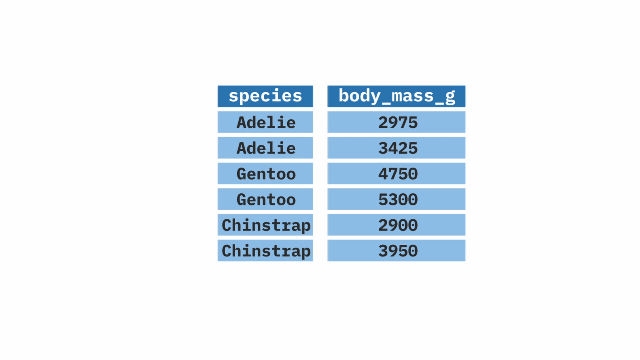
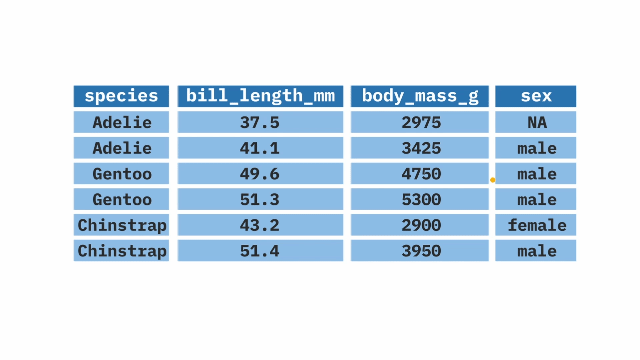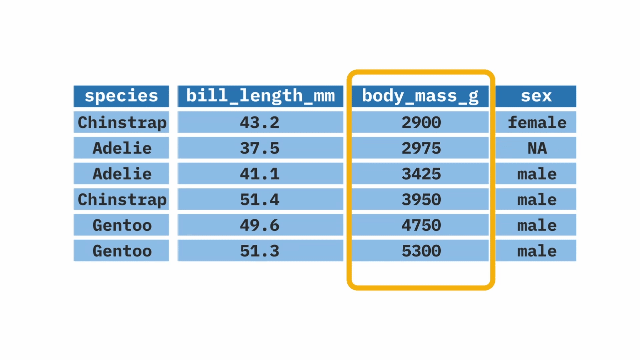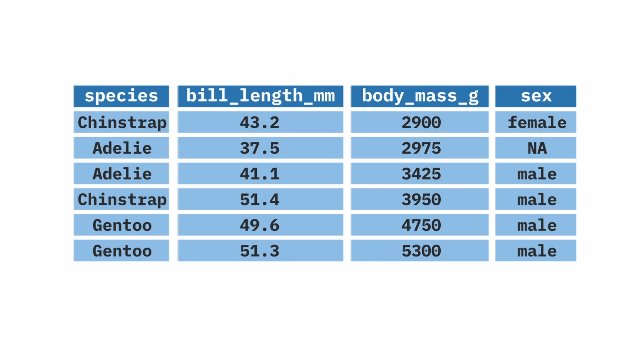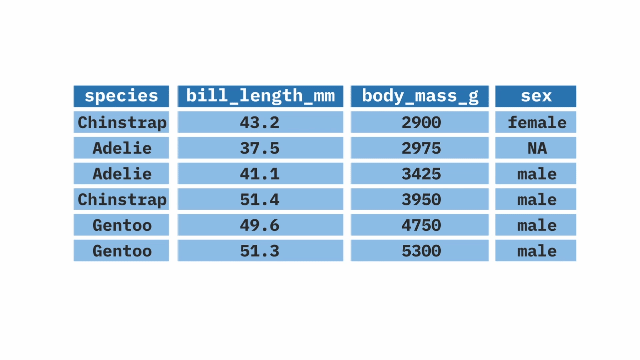
This <- is called the assignment operator. The object <- expression means “assign the value of the result from the operation on the right hand side (expression) to the object on the left hand side (object).” We will use this when we manage data. Take an example we will look at below when we discuss the select function. In this example. We start with the dataset ethiopia. Using the pipe discussed above we will select the variables we want to use for our research. Then assign this new, smaller, dataset to an object named ethiopia_small. Anytime you do data management, remember to use the assignment operator.
1ethiopia_small <- ethiopia |>
2 select(N_REGION_WVS, N_TOWN, G_TOWNSIZE, G_TOWNSIZE2, H_SETTLEMENT, H_URBRURAL, Q34, Q241, Q242, Q243, Q244, Q245, Q246, Q247, Q248, Q249, Q250, Q251, Q252, Q253, Q254)- 1
- Take dataset named ethiopia and after selecting variables create a new dataset ethiopia_small.
- 2
- And then, select only the variables listed.
6.1.3 The $ Operator
Finally. let’s clear up what that $ notation is doing. The dollar sign allows you to specify an item from an object, a dataset, such as a columns—a variable. The left-hand side is the dataset name, and the right-hand side is the variable name. There may be commands that require you to identify a specific variable. For example, you might want to run frequencies for a single variable.
frq(ethiopia_small$Q254)National pride (x) <categorical>
# total N=1230 valid N=1229 mean=1.18 sd=0.51
Value | N | Raw % | Valid % | Cum. %
--------------------------------------------------
Very proud | 1061 | 86.26 | 86.33 | 86.33
Quite proud | 129 | 10.49 | 10.50 | 96.83
Not very proud | 25 | 2.03 | 2.03 | 98.86
Not at all proud | 14 | 1.14 | 1.14 | 100.00
<NA> | 1 | 0.08 | <NA> | <NA>6.2 Select
Each of the datasets you can choose from are big, they you have datasets with a lot of variables. The World Values Survey has 487 variables. The American National Election Study datasets are even bigger. The computer can handle datasets this big, but they are unwieldy. You should choose a subset of variables you want to work with in your research this semester.
To subset a dataset, we’ll use the select function in the {dplyr} package. {dplyr} is part of the {tidyverse}.
Here is a short video (about 3:00) on using the select done by an R user group, R-Ladies Sydney:
Let’s look at an example from the WVS. I have been using Ethiopia. For now, my research question is: Does where a person lives have an impact on Ethiopian’s views on democracy? Looking at the codebook, I see a series of variables on where folks reside and a series of questions on democracy. So I am going to select only the variables I want to look at for now. We can always add to or subtract from this list later.
library(tidyverse)
ethiopia_small <- ethiopia |>
select(N_REGION_WVS, N_TOWN, G_TOWNSIZE, G_TOWNSIZE2, H_SETTLEMENT, H_URBRURAL, Q34, Q241, Q242, Q243, Q244, Q245, Q246, Q247, Q248, Q249, Q250, Q251, Q252, Q253, Q254)A lot of typing! Since these variables are in two groups that are consecutive in the dataset, I can do this by using a shortcut :. This shortcut selects all the variables in a range of consecutive variables. There are a bunch of shortcuts, helpers, for the select function.
library(tidyverse)
ethiopia_small <- ethiopia |>
select(N_REGION_WVS : H_URBRURAL, Q34, Q241 : Q261, E1_LITERACY, Q275R)One helper that I will show you is unselecting variables. Let’s day you don’t want include a couple of variables anymore. We can unselect them by putting the minus (-) sign before them in the select command.
ethiopia_small_2 <- ethiopia_small %>%
select(-E1_LITERACY, -Q275R)This drops two variables, E1_LITERACY and Q275R from our selected variables and creates a new dataset with a new name, ethiopia_small_2.
For more details on using select see either XXX or YYY.

6.3 Filter
When using the select function we worked with columns in our dataset. With the filter command, we will be working with rows. We’ll use the filter function in the {dplyr} package, part of the {tidyverse}.
This 10:00 video from the R Ladies Sydney walks you through using the filter function along with arrange.
To look at an example, using 2022 ANES Pilot Study we could filter to only include respondents who were from big cities. Make sure you use two equal signs == with the filter command!
anes_pilot_small <- anes_pilot_small %>%
filter(urbanicity2 == 1)You can also combine commands. So you could look at Democrats who live in big cities or people who live in big cities and suburban areas. The ampersand (&) is used for and. The straight bar (|) is used for or.
anes_pilot_small <- anes_pilot_small %>%
filter(urbanicity2 == 1 & urbanicity2 == 1)anes_pilot_small <- anes_pilot_small %>%
filter(urbanicity2 == 1 | urbanicity2 == 4)
6.4 Mutate
The mutate function is also in the {dplyr} package, part of the {tidyverse}. Mutate can be used to create new variables or to recode existing variables. Recoding is particularly useful in taking a survey question and creating fewer categories.
You might want to change the shape of a variable. Let’s look at two examples. One is taking a continuous variable and recoding it to be a categorical variable. There are sometimes reasons in doing analysis that we may want to do this. The second is recoding a categorical variable into a new categorical variable.
For this we are going to use another new package, sjmisc.
6.4.1 Recode a new categorical variable from an existing categorical variable
Sometimes you may want to recode your variable so that it has fewer categories. For example, look at the question below from the Ethiopia VWS dataset. It asks how democratically is this country being governed today. There are ten categories, ranging from “Not at all democratic” to “Completely Democratic.”
frq(ethiopia_small$Q251)How democratically is this country being governed today (x) <categorical>
# total N=1230 valid N=1214 mean=5.43 sd=2.99
Value | N | Raw % | Valid % | Cum. %
------------------------------------------------------
Not at all democratic | 218 | 17.72 | 17.96 | 17.96
2 | 54 | 4.39 | 4.45 | 22.41
3 | 46 | 3.74 | 3.79 | 26.19
4 | 73 | 5.93 | 6.01 | 32.21
5 | 282 | 22.93 | 23.23 | 55.44
6 | 123 | 10.00 | 10.13 | 65.57
7 | 94 | 7.64 | 7.74 | 73.31
8 | 89 | 7.24 | 7.33 | 80.64
9 | 37 | 3.01 | 3.05 | 83.69
Completely democratic | 198 | 16.10 | 16.31 | 100.00
<NA> | 16 | 1.30 | <NA> | <NA>This table is hard to interpret. To ease interpretation, we will recode the data into three groups:
- For people who answered 1 through 3. We’ll call this “Not Democratic.”
- For people who answered 4 through 7. We’ll call this “Somewhat Democratic.”
- For people who answered 8 through 10. We’ll call this “Democratic.”
We’ll use the fct_collapse command from forcats, part of the tidyverse here.
Note we gave the new variable a new name—Q251_recode—to distinguish it from Q251. This is good practice. We may want the original variable later!
Look at the frequency of the new variable. It gives us a better picture of how Ethiopians feel about the success of democracy in their country.
load("ethiopia_small.RData")
ethiopia_small <- ethiopia_small |>
as_factor() |>
mutate(Q251_recode = fct_collapse(Q251,
"Not Democratic" = c("Not at all democratic", "2", "3"),
"Somewhat Democratic" = c("4", "5", "6", "7"),
"Democratic" = c("8", "9", "Completely democratic")))
# ethiopia_small$Q251_recode <- fct_collapse(ethiopia_small$Q251,
# "Not Democratic" = c("Not at all democratic", "2", "3"),
# "Somewhat Democratic" = c("4", "5", "6", "7"),
# "Democratic" = c("8", "9", "Completely democratic"))
frq(ethiopia_small$Q251_recode)How democratically is this country being governed today (x) <categorical>
# total N=1230 valid N=1214 mean=2.00 sd=0.73
Value | N | Raw % | Valid % | Cum. %
----------------------------------------------------
Not Democratic | 318 | 25.85 | 26.19 | 26.19
Somewhat Democratic | 572 | 46.50 | 47.12 | 73.31
Democratic | 324 | 26.34 | 26.69 | 100.00
<NA> | 16 | 1.30 | <NA> | <NA>6.4.2 Recode a continuous variable to a categorical variable using values
You might want a continuous variable to be in categories for analysis. The example uses the feeling thermometer in the US Supreme Court in the ANES 2022 Pilot Study dataset. The feeling thermometer ranges from 0 to 100. We will create a new variable that divides the Supreme Court feeling thermometer into three categories based on their values. The categories are:
- Less than 34, recoded to “Negative on SCOTUS”.
- Between 34 and 67, recoded to “Neutral on SCOTUS”.
- Greater than or equal to 68 to “Positive on SCOTUS”.
In case there are values that are not between 0 and 100, we will use the TRUE command and define these values as NAs.
library(sjmisc)
load("anes_pilot_small.RData")
anes_pilot_small <- anes_pilot_small %>%
mutate(ftscotus_3_groups = case_when(ftscotus >= 0 & ftscotus < 34 ~ "Negative on SCOTUS",
ftscotus >= 34 & ftscotus < 67 ~ "Neutral on SCOTUS",
ftscotus >= 68 & ftscotus <= 100 ~ "Positive on SCOTUS",
TRUE ~ NA))
frq(anes_pilot_small$ftscotus_3_groups)x <character>
# total N=1585 valid N=1576 mean=2.02 sd=0.79
Value | N | Raw % | Valid % | Cum. %
---------------------------------------------------
Negative on SCOTUS | 477 | 30.09 | 30.27 | 30.27
Neutral on SCOTUS | 593 | 37.41 | 37.63 | 67.89
Positive on SCOTUS | 506 | 31.92 | 32.11 | 100.00
<NA> | 9 | 0.57 | <NA> | <NA>6.4.3 Recode a continuous variable to a categorical variable into equal sized groups
You might want a continuous variable to be in categories for analysis. The example uses the feeling thermometer in the US Supreme Court in the ANES 2022 Pilot Study dataset. We will divide the feeling thermometer on the US Supreme Court into two categories: “Low Opinion of SCOTUS” and “High Opinion of SCOTUS”. To ease interpretation, we add labels. We will use the mutate command from the dplyr package and the dicho and split_var commands from the sjMisc package. For each new variable, we will do the following:
- Create a new variable with the categorical variable.
- Add value labels using the ordered command.
- After creating the new variable, we will look at the frequency distribution.
library(sjmisc)
load("anes_pilot_small.RData")
anes_pilot_small <- anes_pilot_small %>%
mutate(ftscotus_dicho = dicho(ftscotus))
frq(anes_pilot_small$ftscotus_dicho)x <categorical>
# total N=1585 valid N=1585 mean=0.48 sd=0.50
Value | N | Raw % | Valid % | Cum. %
--------------------------------------
0 | 823 | 51.92 | 51.92 | 51.92
1 | 762 | 48.08 | 48.08 | 100.00
<NA> | 0 | 0.00 | <NA> | <NA>anes_pilot_small$ftscotus_dicho <- ordered(anes_pilot_small$ftscotus_dicho,
levels = c(0,1),
labels = c("Low Opinion of SCOTUS", "High Opinion of SCOTUS"))
frq(anes_pilot_small$ftscotus_dicho)x <ordinal>
# total N=1585 valid N=1585 mean=1.48 sd=0.50
Value | N | Raw % | Valid % | Cum. %
-------------------------------------------------------
Low Opinion of SCOTUS | 823 | 51.92 | 51.92 | 51.92
High Opinion of SCOTUS | 762 | 48.08 | 48.08 | 100.00
<NA> | 0 | 0.00 | <NA> | <NA>The dicho command splits the variable in half. The countries with lower mortality rates are labeled “Low Mortality.” The upper half of countries are labeled “High Mortality.”
Below the split_var command splits the variable, the percentage of women in state legislatures in the States dataset, into thirds. We could change n = to a larger number to create more evenly sized groups. [Many more options are here.][https://strengejacke.github.io/sjmisc/articles/recodingvariables.html]
While we are creating three groups as we did above, this command will create 3 equal sized groups in terms of the number of responses. The earlier example using “case_when” creates equal sized groups in terms of the values of the question.
anes_pilot_small <- anes_pilot_small %>%
mutate(ftscotus_3cat = split_var(ftscotus, n = 3))
anes_pilot_small$ftscotus_3cat <- ordered(anes_pilot_small$ftscotus_3cat,
levels = c(1,2, 3),
labels = c("Low Opinion of SCOTUS", "Medium Opinion of SCOTUS", "High Opinion of SCOTUS"))
frq(anes_pilot_small$ftscotus_3cat)x <ordinal>
# total N=1585 valid N=1585 mean=2.01 sd=0.81
Value | N | Raw % | Valid % | Cum. %
---------------------------------------------------------
Low Opinion of SCOTUS | 521 | 32.87 | 32.87 | 32.87
Medium Opinion of SCOTUS | 534 | 33.69 | 33.69 | 66.56
High Opinion of SCOTUS | 530 | 33.44 | 33.44 | 100.00
<NA> | 0 | 0.00 | <NA> | <NA>
For more uses of the mutate function watch this video.
And this video show how you can use many functions together.
6.5 Summarize
You aren’t likely to need the summarize function that is part of dplyr, but in case you do, this is an clear tutorial. You can also create summaries by groups using the group_by function which is explained in the tutorial.